Your Memory Benchmark Is Lying To You (And The Ranked List Never Changed)
You build a memory system for a long-horizon conversational agent. You run it on a standard benchmark. It retrieves the right answer: the user moved to Austin in summer 2021, and your system found that fact. The benchmark scores it as a miss.
You tweak nothing. You rescore. Now it is a hit.
The ranked list is identical. Not a single retrieved item moved. The only thing that changed was which stored form of the answer the benchmark was willing to accept as correct.
That is not a hypothetical. It is a systematic failure mode in how we evaluate transformed conversational memory.

One Answer, Many Stored Forms
Modern memory systems do not just store raw dialogue turns. They transform them. The same evidence can live in the store as:
- The original turn:
"Yeah I actually just relocated to Austin last summer, it's been great so far." - A derived observation:
"User relocated to Austin in summer 2021." - A canonical fact:
"User lives in Austin (since 2021)."
Now ask the benchmark: "When did the user move to Austin?"
If the retriever surfaces the canonical fact at rank 3, that is obviously useful evidence. But if the benchmark only grants credit to the raw transcript turn ID, it records a miss anyway.
I call this target non-invariance: benchmark conclusions that flip even when the ranked output is held fixed, purely because the evaluation target definition changes.

The Numbers Are Not Small
I rescored fixed ranked outputs from two benchmarks, LoCoMo and LongMemEval-S, across four retrievers:
- Lexical search
all-MiniLM-L6-v2BGE-M3mxbai-embed-large
Each run was scored under three target definitions:
- Raw: only verbatim transcript turns get credit
- Source family: anything derived from the same source turn gets credit
- Canonical: only transformed, non-raw memories get credit
The ranked lists never changed. Only the scoring target did.
Switching the target changes nDCG on 83% to 93% of shared queries
On shared queries where both raw and canonical targets apply, switching only the scoring target changed per-query nDCG on 83.4% to 93.1% of queries across the two benchmarks.
That is not evaluator noise. That is the evaluation environment behaving differently under a hidden assumption.
Canonical beats Raw everywhere, but by wildly different margins
On the canonical-covered shared subset, Canonical beats Raw on every native run. But the size of the gap changes dramatically:
- LoCoMo + BGE-M3:
+0.068nDCG - LongMemEval-S + mxbai-embed-large:
+0.420nDCG
That is roughly a six-fold swing in the apparent quality gap between the same two target choices.
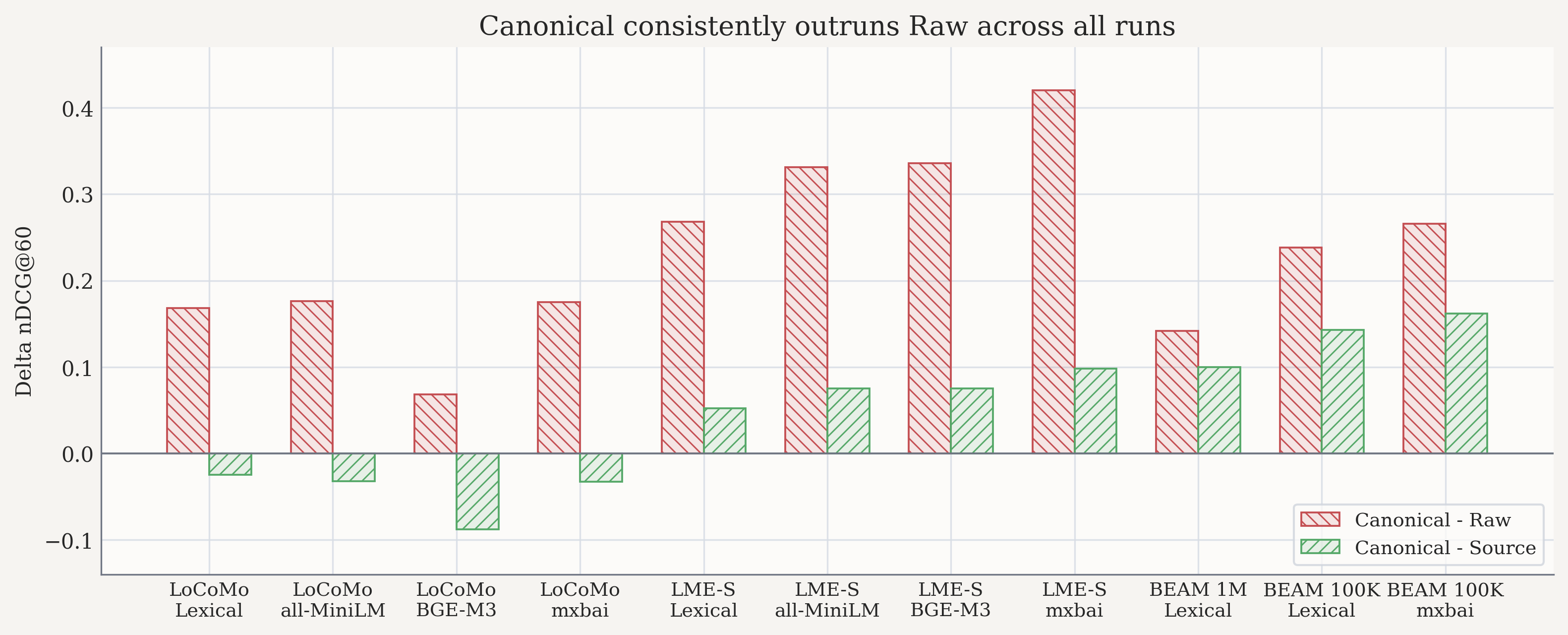
Fixed-subset rescoring on the canonical-covered shared subset
| Dataset | Provider | n | Raw | Source | Canonical | Canonical - Raw | Canonical - Source |
|---|---|---|---|---|---|---|---|
| LoCoMo | Lexical | 899 | 0.1876 | 0.3809 | 0.3556 | +0.168 | -0.025 |
| LoCoMo | all-MiniLM | 899 | 0.2118 | 0.4198 | 0.3875 | +0.176 | -0.032 |
| LoCoMo | BGE-M3 | 963 | 0.2548 | 0.4109 | 0.3231 | +0.068 | -0.088 |
| LoCoMo | mxbai-embed-large | 899 | 0.2120 | 0.4195 | 0.3870 | +0.175 | -0.033 |
| LongMemEval-S | Lexical | 332 | 0.1877 | 0.4041 | 0.4558 | +0.268 | +0.052 |
| LongMemEval-S | all-MiniLM | 332 | 0.2001 | 0.4561 | 0.5309 | +0.331 | +0.075 |
| LongMemEval-S | BGE-M3 | 299 | 0.1969 | 0.4576 | 0.5326 | +0.336 | +0.075 |
| LongMemEval-S | mxbai-embed-large | 332 | 0.1815 | 0.5032 | 0.6015 | +0.420 | +0.098 |
The important part is not just that scores move. It is that they move on the same saved traces.
The Winner Can Flip Even When Nothing About Retrieval Changes
This is the engineering consequence that matters most.
I ran a parser-density sweep where:
F1extracts 1 transformed fact per source turnF5extracts 5 transformed facts per source turnF8extracts 8 transformed facts per source turn
On a fixed shared subset of 453 queries, the preferred configuration flips depending on the target definition.
In the lexical F1 vs F5 comparison:
- Raw prefers the sparser
F1 - Source family prefers the denser
F5 - Canonical goes back to
F1
Across all six pairwise comparisons in the retained fixed-subset sweep:
- Source family prefers the denser store in all 6 of 6 comparisons
- Raw prefers the sparser store in 4 of 6 comparisons
- Canonical splits, with
F1winning 4 of 6 andF8winning bothF5 vs F8comparisons

Target-dependent winner table on the fixed shared subset (n = 453)
| Provider | Comparison | Raw | Source | Canonical |
|---|---|---|---|---|
| Lexical | F1 vs F5 | F1 | F5 | F1 |
| Lexical | F1 vs F8 | F1 | F8 | F1 |
| Lexical | F5 vs F8 | F5 | F8 | F8 |
| all-MiniLM | F1 vs F5 | F1 | F5 | F1 |
| all-MiniLM | F1 vs F8 | F1 | F8 | F1 |
| all-MiniLM | F5 vs F8 | F8 | F8 | F8 |
Same benchmark family. Same underlying evidence. Same fixed subset. Different target, different winner.
It Transfers Across Architectures, But Not In One Clean Direction
I also rescored full runs from two external memory architectures, Mem0 and MemoryOS, on full LoCoMo and LongMemEval-S runs.
The non-invariance survives across both. But the ordering is not uniform:
- Mem0 / LoCoMo: Source > Canonical > Raw
- Mem0 / LongMemEval-S: Source > Raw > Canonical
- MemoryOS / LoCoMo: Source > Raw > Canonical
- MemoryOS / LongMemEval-S: Source > Canonical > Raw
For Mem0 on LongMemEval-S, the stakes are especially clear:
- Source gains
+0.150nDCG over Raw - Canonical falls
-0.131below Raw - Raw-vs-canonical scoring changes MRR on
466 / 470queries
The recent BEAM runs preserve the same story:
- BEAM 1M lexical:
Raw 0.055,Source 0.097,Canonical 0.197 - BEAM 100K lexical:
Raw 0.110,Source 0.206,Canonical 0.349 - BEAM 100K mxbai:
Raw 0.123,Source 0.228,Canonical 0.390
Those absolute scores are lower than LoCoMo and LongMemEval-S, but that does not weaken the claim. In the current harness, BEAM is harsher: it uses much longer turn-sized retrieval rows, and many questions ground to multiple source turns, so it behaves more like an aggregation-heavy long-context stress test.
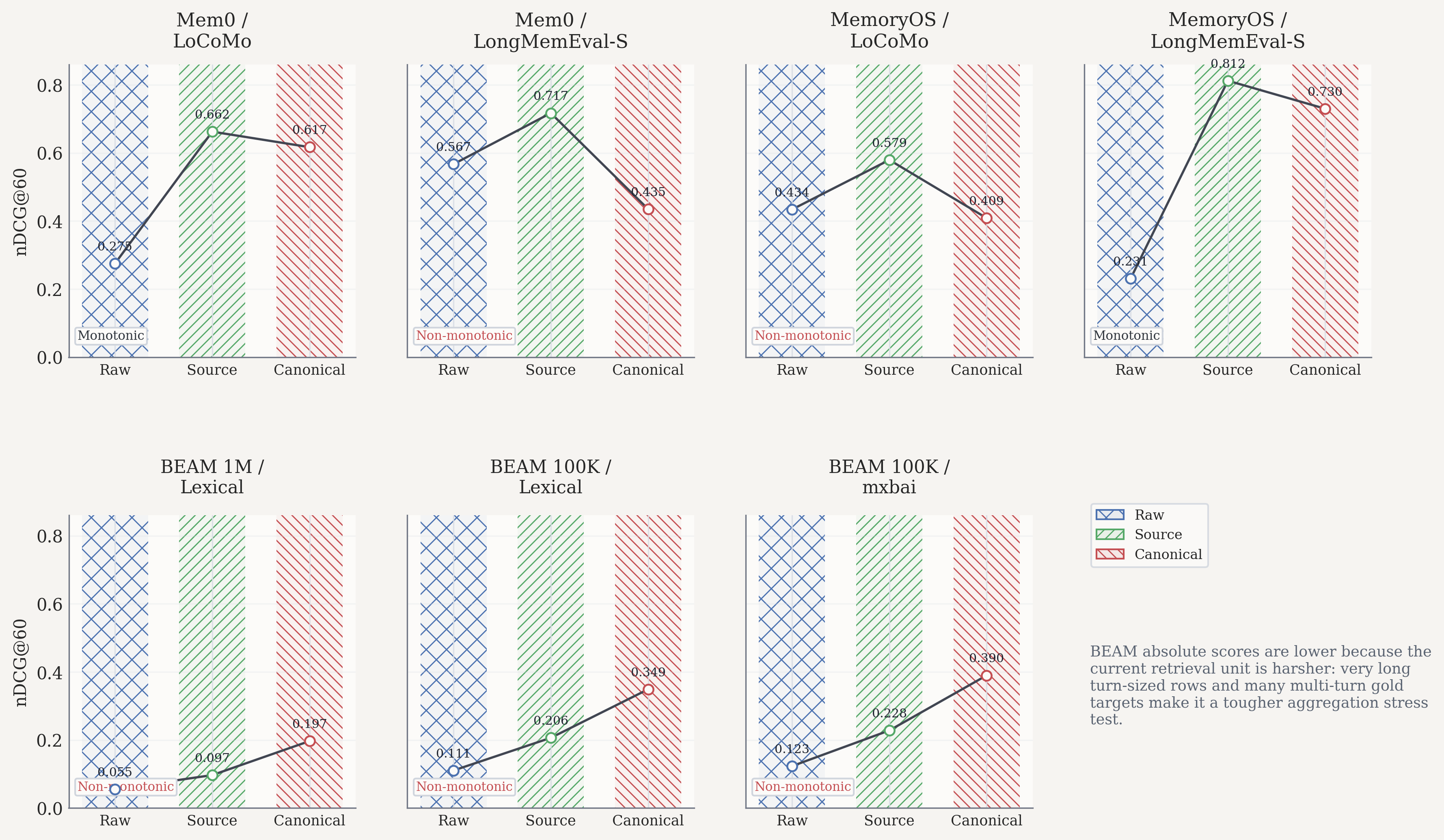
Architectural transfer summary, full-run nDCG@60
| System / Dataset | Raw | Source | Canonical |
|---|---|---|---|
| Mem0 / LoCoMo | 0.2749 | 0.6625 | 0.6169 |
| Mem0 / LongMemEval-S | 0.5670 | 0.7170 | 0.4350 |
| MemoryOS / LoCoMo | 0.4339 | 0.5794 | 0.4086 |
| MemoryOS / LongMemEval-S | 0.2306 | 0.8121 | 0.7298 |
The point is not that abstraction always helps. It is that target choice controls the story.
But Is Extra Credit for Transformed Memories Actually Meaningful?
Fair question.
Maybe a permissive target is just inflating scores by awarding credit to memories that do not really answer the query. So I audited 120 disagreement cases where raw-turn scoring gave no credit but source-family and canonical scoring did.
The results were mixed:
28 / 120fully support the query49 / 120are partially supportive43 / 120do not support it
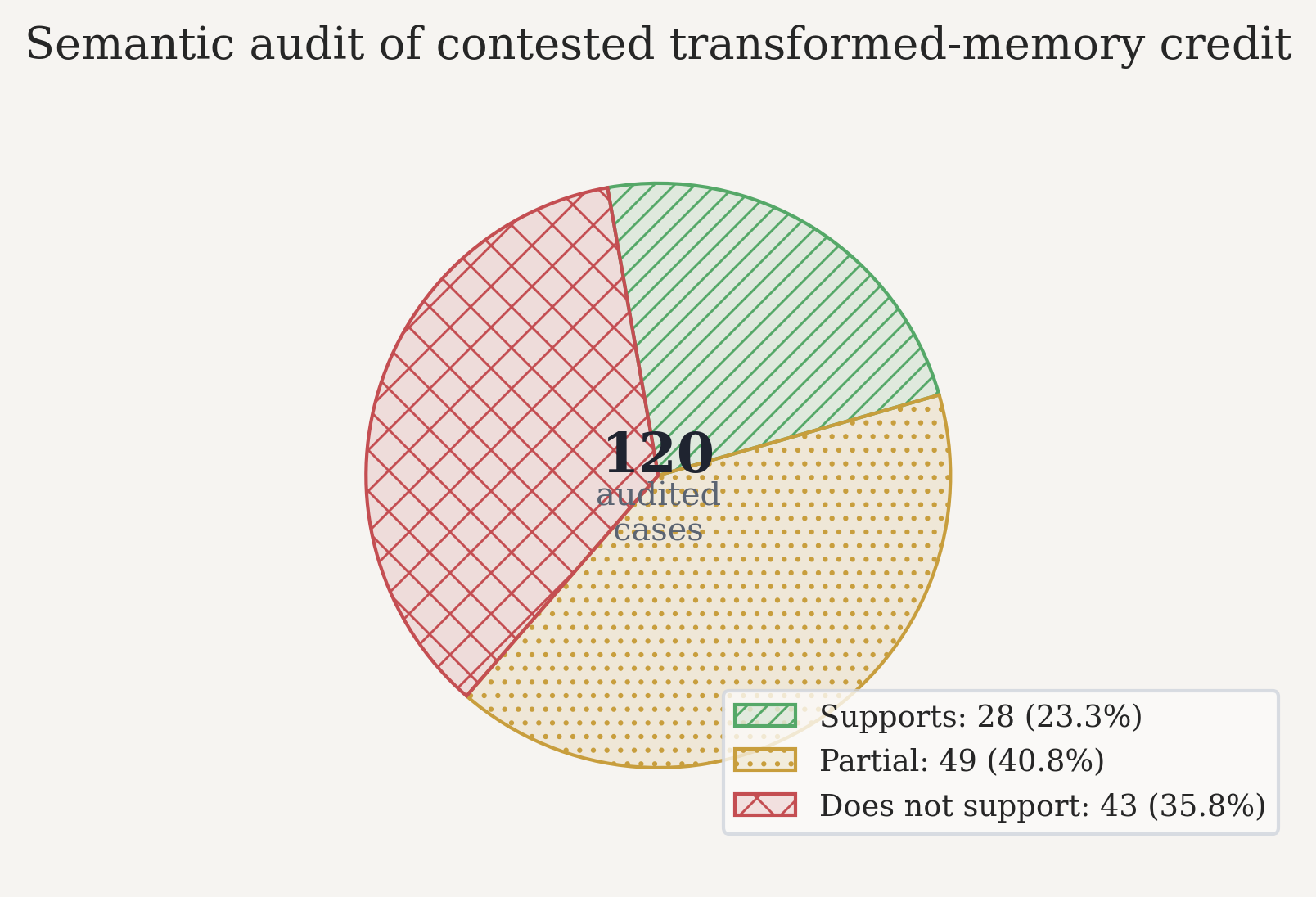
Completed 120-query semantic audit
| Dataset | Supports | Partial | Does not support |
|---|---|---|---|
| LongMemEval-S | 9 | 25 | 26 |
| LoCoMo | 19 | 24 | 17 |
| Total | 28 | 49 | 43 |
Among the non-supportive cases, the dominant failure modes were:
- Missing a required detail such as a date, count, or named entity:
28 / 43 - Retrieving generic background context instead of answer-bearing evidence:
8 / 43 - Retrieving the wrong event or timeline entirely:
7 / 43
That 36% non-support rate applies to the contested disagreement pool, not to all canonical-credit queries. In the two audited runs, that disagreement pool was about 19.9% of canonical-hit queries, which projects to roughly 7.1% of all canonical-hit queries.
So yes, the problem is real. But no, it does not rescue the raw-only benchmark default.
Three Targets, Three Different Questions
These targets are not interchangeable. They answer different evaluation questions.
| Target | What it credits | What it is really asking |
|---|---|---|
| Raw turn | Verbatim source-turn memories only | Did we retrieve the exact utterance history? |
| Source family | Any memory derived from the same source turn | Did we retrieve the right underlying event, regardless of representation? |
| Canonical | Transformed non-raw memories derived from the source turn | Did we retrieve the normalized memory layer intended for serving? |
By construction:
Raw ⊆ Source familyCanonical ⊆ Source familyRawandCanonicalare usually disjoint
That makes Source family a provenance-relaxed upper bound, Raw a strict floor, and Canonical the deployment-aligned target when the product actually serves transformed memory rather than transcript snippets.
What You Should Do
If you are building or benchmarking transformed conversational memory, the reporting policy should change.
- Use Canonical as the primary reported target when the deployed system serves transformed memories or normalized facts.
- Always report Raw alongside it as a floor, especially if your product surfaces transcript snippets or exact provenance matters.
- Use Source family as a stress test, not as a safe standalone leaderboard target.
- Run shared-subset rescoring whenever ontology coverage differs across systems or configurations.
- Inspect query-level disagreement before pretending target choice is innocuous. In these runs, raw-vs-canonical switching changed nDCG on 83% to 93% of shared queries.
- Flag winner flips. If one target recommends a different system or store density, that disagreement is a result, not an annoyance to smooth away.
The Bottom Line
If your memory benchmark can score the same ranked list as both a miss and a hit, depending only on which stored representation it is willing to count as correct, then the benchmark is not measuring a stable property of retrieval quality.
It is measuring retrieval quality plus an unspoken ontology choice.
That choice needs to be explicit.
End
The full paper is in the works.