For Strong Readers, Evidence Compression Is a Coin Flip
You compress retrieved evidence before passing it to a reader model. The reader gets a cleaner, shorter input. Accuracy goes up.
That is the standard story. It is also incomplete.
I tested twenty reader models across twelve families, from Llama 8B to Grok. For the smallest models, compression rescues three rows for every one it breaks. For the strongest, it is a coin flip. The help-to-damage ratio collapses from 3:1 to 1:1.
The aggregate number hides this completely.
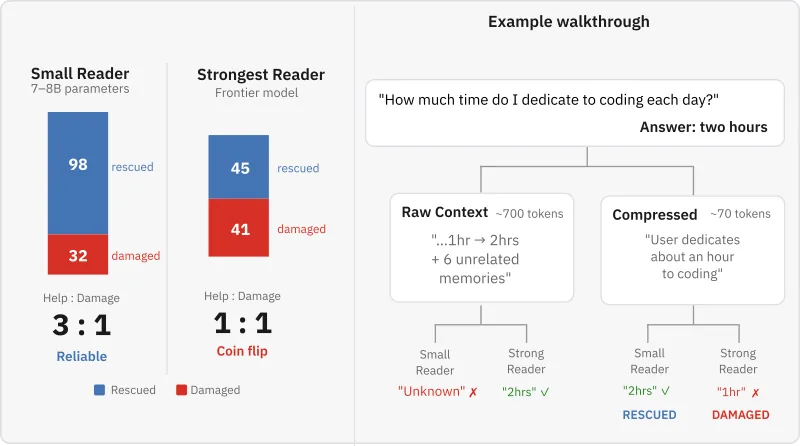
The Setup
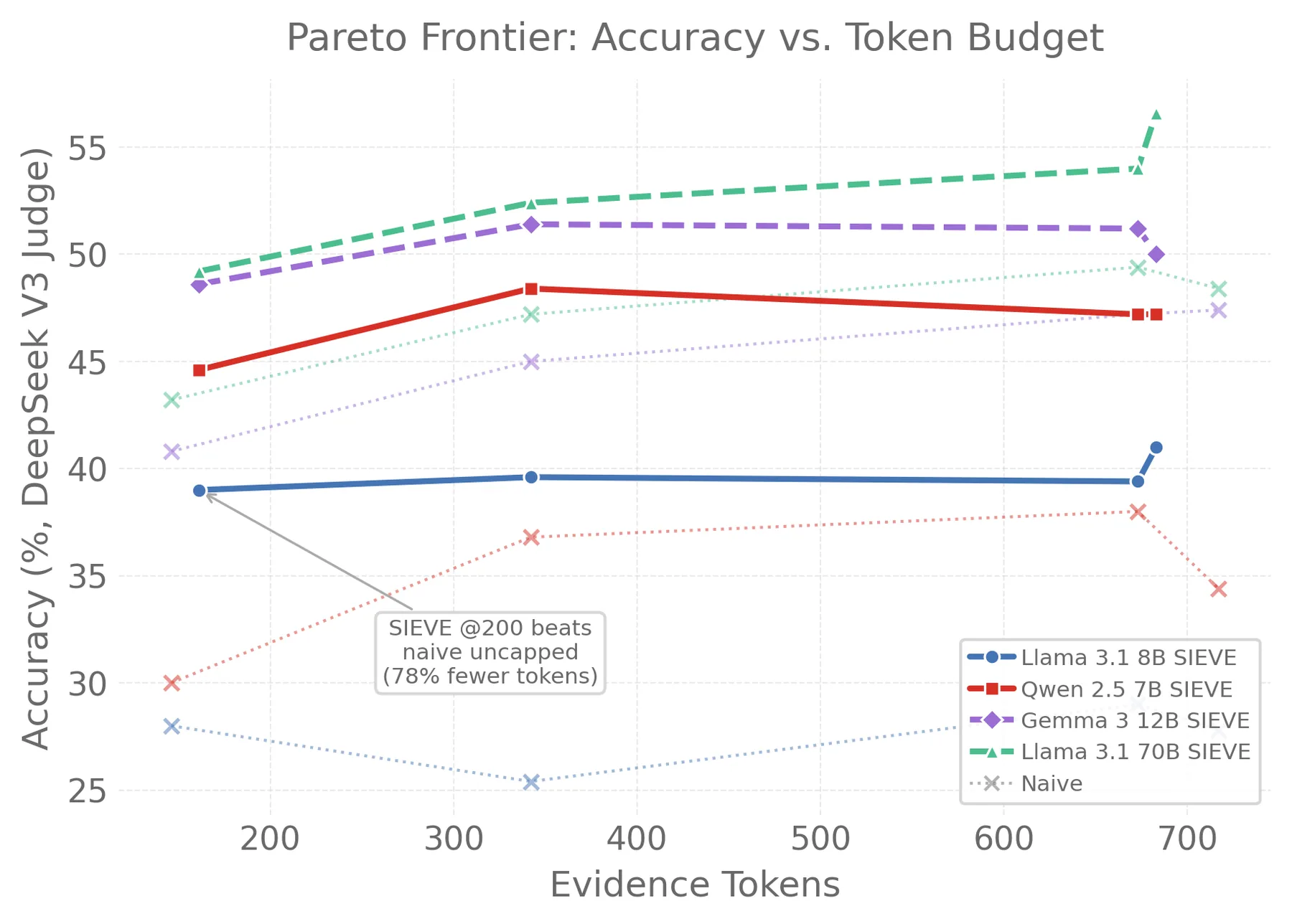
I built a compression pipeline called SIEVE that uses typed extraction schemas for different question types (temporal, preference, factual, etc.). Evidence is compiled once with a single 8B model and replayed across all twenty readers. This means every reader sees the exact same compressed evidence. The only variable is the reader itself.
I also tested four other compression methods: LLMLingua-2 (token pruning at 30%, 50%, and 70% retention), a generic LLM summarizer, a rule-based extraction ablation, and RECOMP (a trained T5-based compressor). Five QA domains: LongMemEval, HotpotQA, LoCoMo, MuSiQue, and ConvoMem.
The correlation between reader baseline accuracy and compression gain is $r = -0.886$ across twenty models. For RECOMP on HotpotQA, it is $r = -0.994$. Near-perfect inverse.
Two Mechanisms, One Crossover
Tracking what happens to each individual row reveals something the aggregate hides.
Small models (7-8B) abstain on 37-43% of answerable questions when given raw context. They see 700 tokens of noisy conversation and give up. Compression reduces false abstention by 25-32%. That is the rescue mechanism.
Strong models rarely abstain. Their gains, when they exist, come from answer quality improvement. The compressed evidence is not just shorter. It is structured. The reader extracts a better answer from it.
These two mechanisms shift continuously with baseline accuracy. The crossover is at roughly 35-40% naive accuracy.
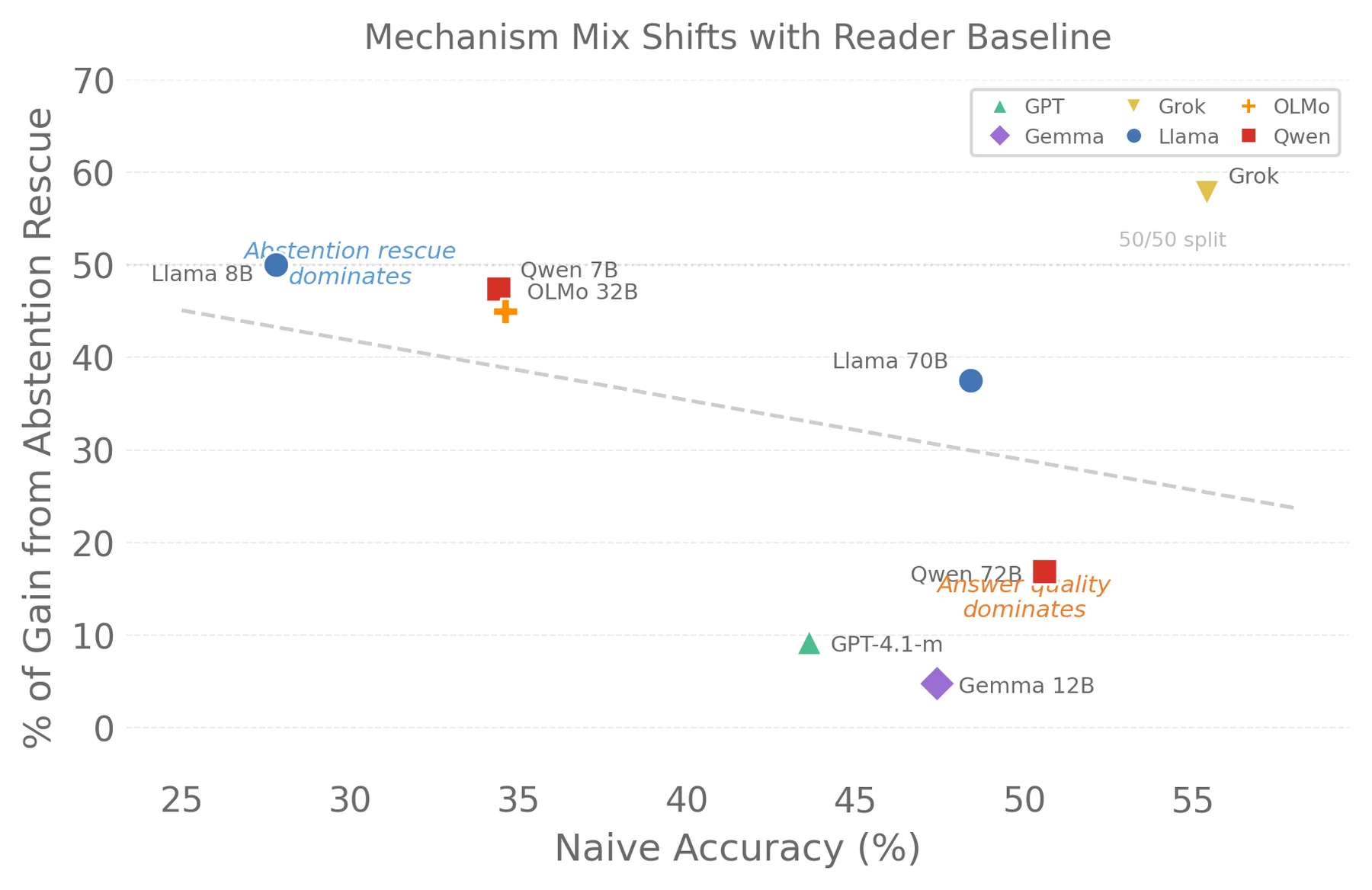
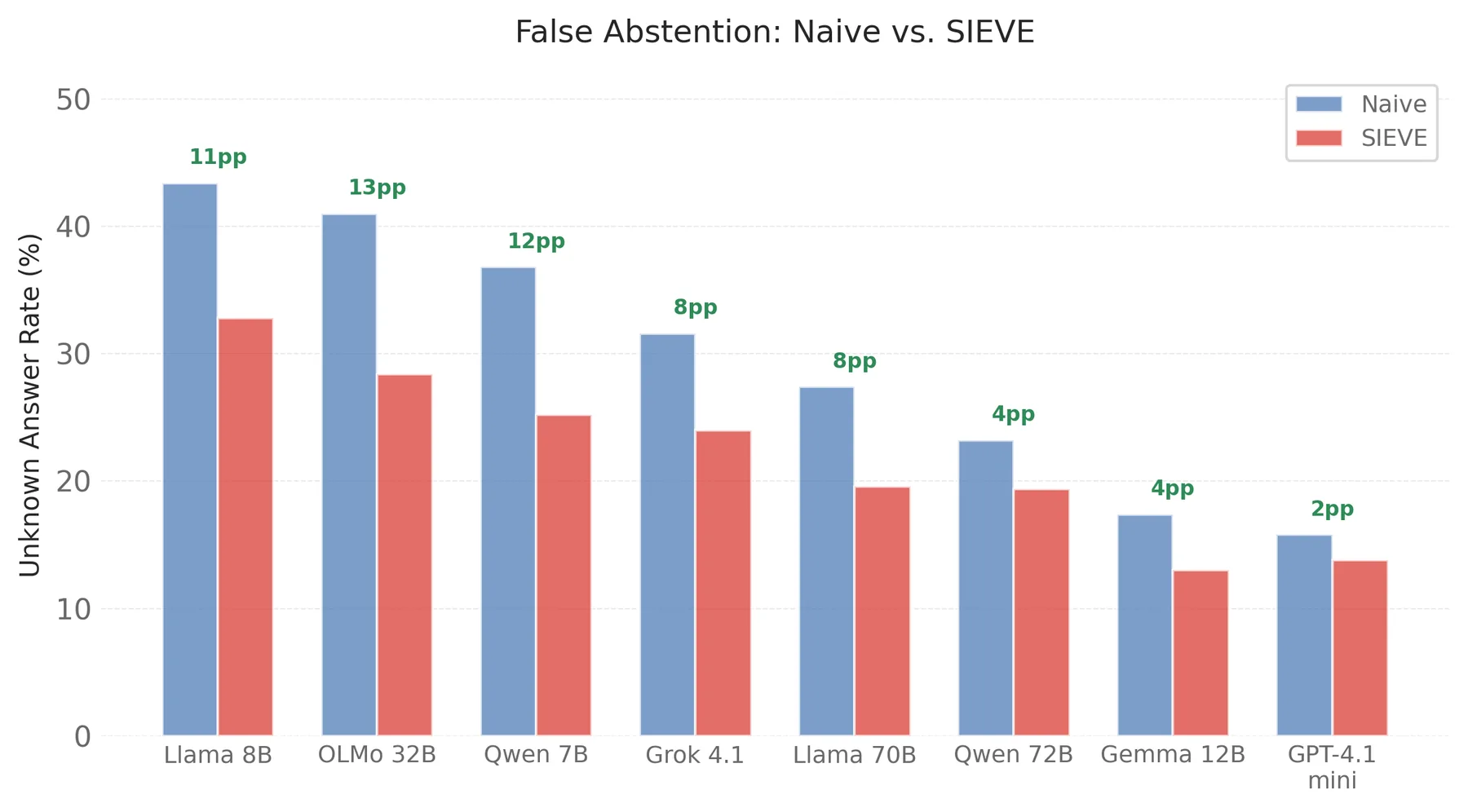
15% of Correct Rows Get Broken
This is the part that matters for deployment.
I classified every row into four outcomes: the reader went from wrong to correct (rescued), from unknown to correct (also rescued), stayed the same, or went from correct to wrong (damaged).
Across all eight models I decomposed, 15.3% of rows the reader already answered correctly were broken by compression. That is 261 out of 1,711 correct-answer pairs. The compiler selected the wrong framing, dropped a critical fact, or overwrote a current answer with a stale one.
For small readers, this damage is outweighed by the rescue rate. For strong readers, the rescue pool shrinks while the damage pool stays the same. That is why the ratio collapses.
Not All Questions Are Equal
The most useful finding is the per-question-type breakdown.
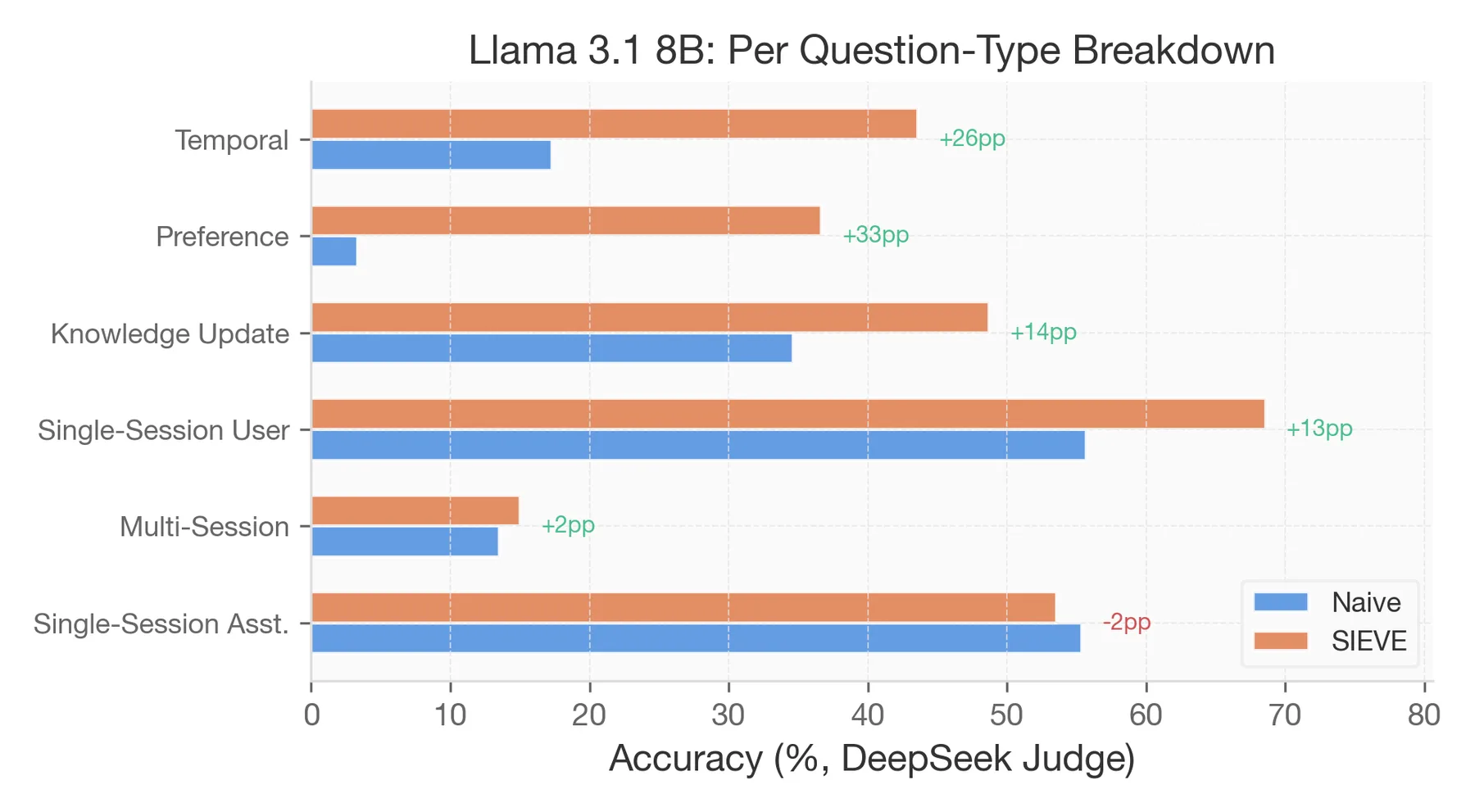
Temporal reasoning questions gain +15 to +39pp across 7 of 8 models. This holds for both small and large readers. The compiler extracts date pairs and event sequences that the reader could not isolate from noisy context.
Preference questions are rescued across all models (+3 to +33pp). The compiler pulls out the user's stated preference and hands it directly to the reader.
Knowledge-update questions regress for strong readers (-1 to -10pp). The compiler sometimes picks the old state of a fact when the reader already had the current one. All 14 temporal-supersession errors in my error taxonomy were concentrated in this one question type.
Multi-session is flat regardless of reader or compression method. BM25 top-20 retrieves 3-4 of 5+ relevant sessions. Compression cannot conjure missing evidence.
Token Pruning Never Helps
I tested LLMLingua-2 at three retention rates: 30%, 50%, and 70%.
| Retention | 8B Accuracy | 8B Delta | 70B Accuracy | 70B Delta | Actual Tokens |
|---|---|---|---|---|---|
| Naive (no compression) | 27.8% | -- | 48.4% | -- | ~717 |
| LLMLingua-2 @30% | 16.8% | -11.0 | 28.0% | -20.4 | ~367 |
| LLMLingua-2 @50% | 23.0% | -4.8 | 41.4% | -7.0 | ~684 |
| LLMLingua-2 @70% | 27.2% | -0.6 | 48.0% | -0.4 | ~1016 |
| LLM-Summarize | 44.4% | +16.6 | 54.2% | +5.8 | ~27 |
| SIEVE | 41.0% | +13.2 | 56.6% | +8.2 | ~683 |
At 30%, token pruning destroys coherence. Retained fragments are not parseable. At 70%, it barely compresses (88% actual retention) and achieves nothing. There is no sweet spot where token pruning helps.
Meanwhile, LLM-Summarize produces 27-token coherent summaries and gains +16.6pp for the small reader. The dividing line is not how much you compress. It is whether the output is coherent.
The Practical Move
The lesson is not "skip compression for strong readers." Llama 70B gains +8.2pp overall, with +15-30pp on temporal and preference questions. Blanket compression is the problem, not compression itself.
For small readers, compress everything. Any coherence-preserving method works. Even a one-line "summarize what's relevant" prompt gains +16pp.
For large readers, route by question type. I tested a trivial 3-line router: always compress temporal and preference, skip knowledge-update if the reader is strong, compress everything else. It eliminates 6-11 damaged rows per model while preserving all gains. The routing itself is free because question-type classification already happens in the pipeline via SpaCy.
What This Means for RAG Systems
If you are deploying a RAG system with evidence compression, the current evaluation standard is misleading. Testing with one reader model and reporting aggregate accuracy gain tells you almost nothing about what will happen when you swap the reader.
Report gains and damage separately. Test across at least two reader scales. Break results down by question type. The interaction is real, it replicates across five domains, and it holds for both trained and untrained compressors.
The paper is under review. Code and data will be released on publication.